Яндекс.Вебмастер представил валидатор микроразметки
2010-12-20 12:27
Яндекс.Вебмастер сообщил о появлении нового инструмента – валидатора микроразметки, предназначенного для того, чтобы облегчить владельцам сайтов работу с разметкой страниц микроформатами. С помощью нового инструмента можно проверить, как поисковый робот Яндекса видит и обрабатывает семантическую разметку той или иной страницы, а также выяснить, есть ли в коде разметки ошибки, которые могут помешать корректной обработке данных.
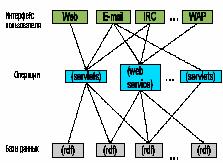
Микроформаты – это стандарт семантической разметки, разработанный специально для структурирования информации на странице для программ-обработчиков. Микроформаты позволяют указать поисковому роботу на смысловое значение отдельных фрагментов страницы и используются для передачи сведений об организации, товарах, отзывах, рецептах.
Сейчас Яндекс поддерживает четыре вида микроформатов:
Также поддерживается microdata – международный стандарт семантической разметки, позволяющий с помощью атрибутов описать смысл информации, содержащейся в HTML-коде страниц. Такие атрибуты позволяют роботам-обработчикам находить и извлекать нужные данные. Про этот стандарт слышу впервые...Погуглив немного выясняем - микроданные как стандарт де-юре еще не приняты - на сайте консорциума W3C есть документ от 19 октября 2010 года - Рабочий проект HTML Microdata, поэтому мной ранее не рассматривались. Будет принят по всей видимости "де-факто".
(Подробнее про микроданные для Google-Yahoo!-Bing июнь 2011.)
В настоящий момент в Яндексе микроданные используются для разметки словарных и энциклопедических статей, терминов и определений.
Подробнее узнать о том, какие данные можно передать Яндексу, можно на странице «Передача данных о содержимом сайта». А о микроформатах и микроданных можно прочесть в разделе Помощи.
Ссылка про все микроформаты (eng).
По этому поводу следует заметить, что Google уже давно поддерживает микроформаты, а также семантическую разметку RDFa, и по своему движению более приближен к общей тенденции Semantic Web. Рано или поздно Яндекс перейдет на поддержку и RDFa. Подробнее об использовании микроформатов для индексатора Гугл можно прочитать в его справке, а проверить страницы можно при помощи Google Web Master Tools. Список микроформатов, используемых роботами Google несколько отличается от Яндекса и более широк.
Проблема же заключается в том, что когда сайт создается "ручками", внедрить микроформаты просто, однако очень трудоемко. На сегодняшний день пока нет инструментария для автоматизированного добавления микроформатов в текст html-кода. Вторая проблема - большинство веб-разработчиков пользуется CMS, что естественно облегчает работу, однако не позволяет работать с html-кодом, либо внедрение микроформатов еще более усложняется. Поэтому большинство разработчиков с микроформатами "не заморачивается".
О пользе использования микроформатов и RDF говорить не приходится - используя их уже лет семь-восемь, могу сказать, что сайт и раскручивается быстрее, и повышается релевантность поиска, позиционирование его в результатах.
Стоит также дополнить список микроформатов, которые следует использовать веб-мастерам для улучшения позиционирования и распознавания поисковыми роботами своего сайта (в свете движения к Semantic Web):
Подробнее про общий принцип построения Semantic Web и увидеть более полный перечень микроформатов можно в разделе 5. Метаданные в статье "SEMANTIC WEB КАК НОВАЯ МОДЕЛЬ ИНФОРМАЦИОННОГО ПРОСТРАНСТВА ИНТЕРНЕТ" (см. в Разделе "Публикации" блога за 2008 г.).
За саму новость спасибо сайту searchengines.ru Дополнения-размышлизмы мои :).
Даешь RDF в массы! Автоматизацию семантической разметки - в каждый компьютер! Все дружно на построение светлого Semantic Web будущего! :))
2010-12-20 12:27
Яндекс.Вебмастер сообщил о появлении нового инструмента – валидатора микроразметки, предназначенного для того, чтобы облегчить владельцам сайтов работу с разметкой страниц микроформатами. С помощью нового инструмента можно проверить, как поисковый робот Яндекса видит и обрабатывает семантическую разметку той или иной страницы, а также выяснить, есть ли в коде разметки ошибки, которые могут помешать корректной обработке данных.
Микроформаты – это стандарт семантической разметки, разработанный специально для структурирования информации на странице для программ-обработчиков. Микроформаты позволяют указать поисковому роботу на смысловое значение отдельных фрагментов страницы и используются для передачи сведений об организации, товарах, отзывах, рецептах.
Сейчас Яндекс поддерживает четыре вида микроформатов:
- hCard - формат разметки контактной информации (адресов, телефонов и т.д. Довольно старый и хорошо зарекомендовавший себя стандарт. Входит в состав рекомендованных к использованию консорциумом W3C для Semantic Web. Полезен для указания на странице контактной информации о фирме и т.п.
- hRecipe - формат для описания кулинарных рецептов. Стандарт довольно новый. Используется очень редко (по моим наблюдениям ИМХО). В состав рекомендованных к использованию консорциумом W3C для Semantic Web не входит, хотя стандарты, пополняющие список рекомендаций консорциума, становятся стандартами "де факто". Поэтому при определенной популярности он таковым может стать. Гугл его поддерживает, но для рецептов он также поддерживает еще ряд стандартов.
- • hReview - формат разметки отзывов. Также входит в состав рекомендованных к использованию консорциумом W3C для Semantic Web. Индексатором Google используется наравне с микроданными и RDFa.
- • hProduct - формат разметки товаров. Также входит в состав рекомендованных к использованию консорциумом W3C для Semantic Web. Очень полезен для интернет-магазинов. Давно активно используется такими гигантами, как Amazon и т.п. Google поддерживает наравне с более расширенными возможностями.
Также поддерживается microdata – международный стандарт семантической разметки, позволяющий с помощью атрибутов описать смысл информации, содержащейся в HTML-коде страниц. Такие атрибуты позволяют роботам-обработчикам находить и извлекать нужные данные. Про этот стандарт слышу впервые...Погуглив немного выясняем - микроданные как стандарт де-юре еще не приняты - на сайте консорциума W3C есть документ от 19 октября 2010 года - Рабочий проект HTML Microdata, поэтому мной ранее не рассматривались. Будет принят по всей видимости "де-факто".
(Подробнее про микроданные для Google-Yahoo!-Bing июнь 2011.)
В настоящий момент в Яндексе микроданные используются для разметки словарных и энциклопедических статей, терминов и определений.
Подробнее узнать о том, какие данные можно передать Яндексу, можно на странице «Передача данных о содержимом сайта». А о микроформатах и микроданных можно прочесть в разделе Помощи.
Ссылка про все микроформаты (eng).
По этому поводу следует заметить, что Google уже давно поддерживает микроформаты, а также семантическую разметку RDFa, и по своему движению более приближен к общей тенденции Semantic Web. Рано или поздно Яндекс перейдет на поддержку и RDFa. Подробнее об использовании микроформатов для индексатора Гугл можно прочитать в его справке, а проверить страницы можно при помощи Google Web Master Tools. Список микроформатов, используемых роботами Google несколько отличается от Яндекса и более широк.
Проблема же заключается в том, что когда сайт создается "ручками", внедрить микроформаты просто, однако очень трудоемко. На сегодняшний день пока нет инструментария для автоматизированного добавления микроформатов в текст html-кода. Вторая проблема - большинство веб-разработчиков пользуется CMS, что естественно облегчает работу, однако не позволяет работать с html-кодом, либо внедрение микроформатов еще более усложняется. Поэтому большинство разработчиков с микроформатами "не заморачивается".
О пользе использования микроформатов и RDF говорить не приходится - используя их уже лет семь-восемь, могу сказать, что сайт и раскручивается быстрее, и повышается релевантность поиска, позиционирование его в результатах.
Стоит также дополнить список микроформатов, которые следует использовать веб-мастерам для улучшения позиционирования и распознавания поисковыми роботами своего сайта (в свете движения к Semantic Web):
- - основа основ - стандарт Dublin Core
- - очень широко используемый стандарт Topic Maps (XMT) – стандарт ISO (ISO/IEC 13250:2003) для представления и обмена знаниями с точки зрения поиска информации
- vCard - аналог hCard
- - формат FOAF - информация о людях и их "дружественных отношениях".
- - ну и главный формат описания ресурсов - RDF - RDFa. Надо добавить, что поддержка RDFa включена в стандарт HTML5
Подробнее про общий принцип построения Semantic Web и увидеть более полный перечень микроформатов можно в разделе 5. Метаданные в статье "SEMANTIC WEB КАК НОВАЯ МОДЕЛЬ ИНФОРМАЦИОННОГО ПРОСТРАНСТВА ИНТЕРНЕТ" (см. в Разделе "Публикации" блога за 2008 г.).
За саму новость спасибо сайту searchengines.ru Дополнения-размышлизмы мои :).
Даешь RDF в массы! Автоматизацию семантической разметки - в каждый компьютер! Все дружно на построение светлого Semantic Web будущего! :))