
РАЗРАБОТКА РАСПРЕДЕЛЕННЫХ СЕМАНТИЧЕСКИХ ПРИЛОЖЕНИЙ КАК СТРАТЕГИЯ РАЗВИТИЯ СОВРЕМЕННОГО WEB (Продолжение)
Начало -- 2 -- -- 3 -- 4 -- 5 --
Унифицированный шаблон семантического приложения Web
Web, в отличие от понятия Интернет, представляет собой сеть html-документов, связанных между собой гиперссылками. Семантический веб (Semantic Web) на данный момент представляет собой RDF-документы и базы данных, машинно-обрабатываемые данные, онтологии и подсистемы логического вывода [5]. Вопросы доказательства и доверия пока остаются открытыми.
Semantic Web представляет собой уровень открытой базы данных, надстроенный над вебом (см. Рисунок 1) [4].
 |
| Рисунок 1. Semantic Web как уровень открытой базы данных в Web. |
Базовые открытые стандарты Semantic Web следующие:
- RDF - обеспечивает хранение данных в виде троек;
- OWL - определяет системы концептов, называемые онтологиями;
- SPARQL - язык запросов к RDF;
- SWRL - определяет правила;
- GRDDL - предназначен для преобразования данных в формат RDF.
Семантическое приложение Web - это приложение, которое работает в соответствии со стандартами Semantic Web, создает и использует "машинно-читаемые" данные и обладает конструктивными особенностями веба, например, работает с распределенными онтологиями и/или данными.
Кроме того, необходимо отметить, что семантическое приложение должно воспринимать открытый мир; это значит, что оно должно знать, что информация никогда не бывает полной.
Во-вторых, приложение должно использовать некоторое формальное описание семантики данных.
В-третьих, семантическое приложение должно использовать информационные источники, которые:
- географически распределены;
- имеют разных собственников, и, следовательно, отсутствует контроль за развитием данного источника;
- являются гетерогенными (синтаксически, структурно и семантически);
- содержат данные реального мира, т.е. источники должны быть относительно большими.
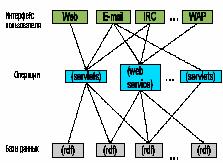 |
| Рисунок 2. Архитектура семантических приложений Semantic Web |
Таким образом, семантическое приложение обязано уметь обрабатывать RDF-тройки и обеспечивать соответствующие шаблоны GRDDL для отображения существующих источников данных в RDF. Кроме того, необходимо иметь возможность в приемлимые сроки получать доступ к RDF-тройкам через веб-сервисы, сервлеты или другое программное обеспечение с открытым для использования API. И последняя компонента, одна из наиболее сложных, - интерфейс пользователя, который должен поддерживать доступ с различных устройств, различные протоколы и типы доступа. Все компоненты семантического приложения должны поддерживать стандарты Semantic Web, утвержденные консорциумом W3C, для обеспечения способности к взаимодействию с различными системами на разных уровнях.
Таким образом, для реализации семантического приложения необходима реализация следующего минимального набора компонент:
1. Хранилища RDF-триплетов.
2. Средства обработки RDF-триплетов.
3. Средства визуализации RDF-триплетов.
4. Интерфейс пользователя.
5. Средства интеграции со сторонними сервисами.
На сегодняшний день эффективные компоненты 1,2 уже реализованы и могут быть подобраны с учетом специфики семантического приложения. Компоненты 3-5 должны быть реализованы с учетом специфики задачи, которую необходимо решить. Несмотря на широкий круг задач, которые можно решать с помошью Semantic Web, предложим унифицированный набор компонентов (шаблон), которые можно применить в любом семантическом приложении:
1) Набор предопределенных Sparql-запросов, которые позволят дать базовую функциональность приложению и типовой интерфейс пользователя.
2) Система рейтингования выводимой информации (предопределенный набор фильтров).
3) Ассистент запросов - средство для упрощения создания произвольных запросов к приложению. Это необходимо прежде всего для оценки сложности запроса, вводимого пользователем, и предотвращения возможности выполнения заведомо невыполнимых запросов.
4) Аггрегатор RSS/Atom новостных лент для обеспечения возможности пополнения приложения новой информацией.
Как можно заметить, все предложенные компоненты направлены на ограничение возможностей пользователя в доступе к данным, которые можно было получить через открытую среду Semantic Web. Это связано, прежде всего, с необходимостью учитывать вопросы производительности приложения при подключении большого числа пользователей и возможностью создания запросов в Semantic Web, которые не могут быть выполнены за конечное время. Это может привести к тому, что пользователь не дождется конца выполнения запроса и вынужден будет поменять провайдера приложений.
Дальше
Начало -- 2 -- -- 3 -- 4 -- 5 --
















No comments:
Post a Comment